- PL: Ta strona nie jest tłumaczona na polski.
CUDA Cheat sheet
CUDA is an acronym for “Compute Unified Device Architecture”. Some frequently used commands/qualifiers/concepts are listed below for convenience.
Cuda Memory Model

Variable Type Qualifiers
| Variable declaration | Memory | Scope | Lifetime | Performance penalty |
|---|---|---|---|---|
int localVar; |
register | thread | thread | ~ 1x |
__local__ int localVar; |
register | thread | thread | ~ 1x |
int localArray[10]; |
local | thread | thread | ~ 100x |
__shared__ int sharedVar; |
shared | block | block | ~ 1x |
__device__ int globalVar; |
global | grid + host | application | ~ 100x |
__constant__ int constantVar; |
constant | grid + host | application | ~ 1x |
Notes:
- Automatic variables without any qualifier reside in a register – Except arrays that reside in local memory.
-
__device__is optional when used with__local__,__shared__, or__constant__ -
Registers: The fastest form of memory on the multi-processor. Is only accessible by the thread. Has the lifetime of the thread.
- Shared Memory: Can be as fast as a register when there are no bank conflicts or when reading from the same address. Accessible by any thread of the block from which it was created. Has the lifetime of the block.
- Constant Memory: Accessible by all threads. Lifetime of application. Fully cached, but limited.
- Global memory: Potentially 150x slower than register or shared memory -- watch out for uncoalesced reads and writes. Accessible from either the host or device. Has the lifetime of the application - it is persistent between kernel launches.
- Local memory: A potential performance gotcha, it resides in global memory and can be 150x slower than register or shared memory. Is only accessible by the thread. Has the lifetime of the thread.
Notes:
Because the shared memory is on-chip, it is much faster than local and global memory. In fact, shared memory latency is roughly 100x lower than uncached global memory latency (provided that there are no bank conflicts between the threads). Shared memory is allocated per thread block, so all threads in the block have access to the same shared memory. Threads can access data in shared memory loaded from global memory by other threads within the same thread block.
When accessing multidimensional arrays it is often necessary for threads to index the higher dimensions of the array, so strided access is simply unavoidable. We can handle these cases by using a type of CUDA memory called shared memory. Shared memory is an on-chip memory shared by all threads in a thread block. One use of shared memory is to extract a 2D tile of a multidimensional array from global memory in a coalesced fashion into shared memory, and then have contiguous threads stride through the shared memory tile. Unlike global memory, there is no penalty for strided access of shared memory.
Readings:
https://www.3dgep.com/cuda-memory-model/
https://www.microway.com/hpc-tech-tips/gpu-memory-types-performance-comparison/
https://developer.nvidia.com/blog/using-shared-memory-cuda-cc/
https://www.ce.jhu.edu/dalrymple/classes/602/Class13.pdf
Programming model

Functions qualifers
__global__ // launched by CPU on device (must return void)
__device__ // called from other GPU functions (never CPU)
__host__ // launched by CPU on CPU (can be used together with __device__)
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#function-declaration-specifiers
Copying memory
The memory between host and device can be copied in two ways.
- The synchronous call blocks the CPU until the copy is complete. Copy begins when all preceding CUDA calls are completed.
cudaMemcpy (void ∗dst, const void ∗src, size_t count, enum cudaMemcpyKind kind)
// enum cudaMemcpyKind
// cudaMemcpyHostToDevice = 1
// cudaMemcpyDeviceToHost = 2
- An asynchronous call which does not block the CPU is
cudaError_t cudaMemcpyAsync ( void* dst, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream = 0 )
A stream in CUDA is a sequence of operations that execute on the device in the order in which they are issued by the host code. While operations within a stream are guaranteed to execute in the prescribed order, operations in different streams can be interleaved and, when possible, they can even run concurrently.
Kernel launch
Kernel launches are asynchronous - Control returns to the CPU immediately. According to documentation the execution configuration is defined as follows:
f_name<<<dim3 gridDim, dim3 blockDim, size_t sharedMem, cudaStream_t strId>>>(p1,... pN)
// sharedMem - specifies the number of bytes in shared memory that is dynamically allocated per block for this call in addition to the statically allocated memory.
// strId - specifies the associated stream, is an optional parameter which defaults to 0.
To block the CPU until all preceding CUDA calls have completed call:
cudaDeviceSynchronize()
To synchronize threads within a kernel:
__syncthreads()
Cores, Schedulers and Streaming Multiprocessors
GPUs are designed to apply the same function to many data simultaneously.
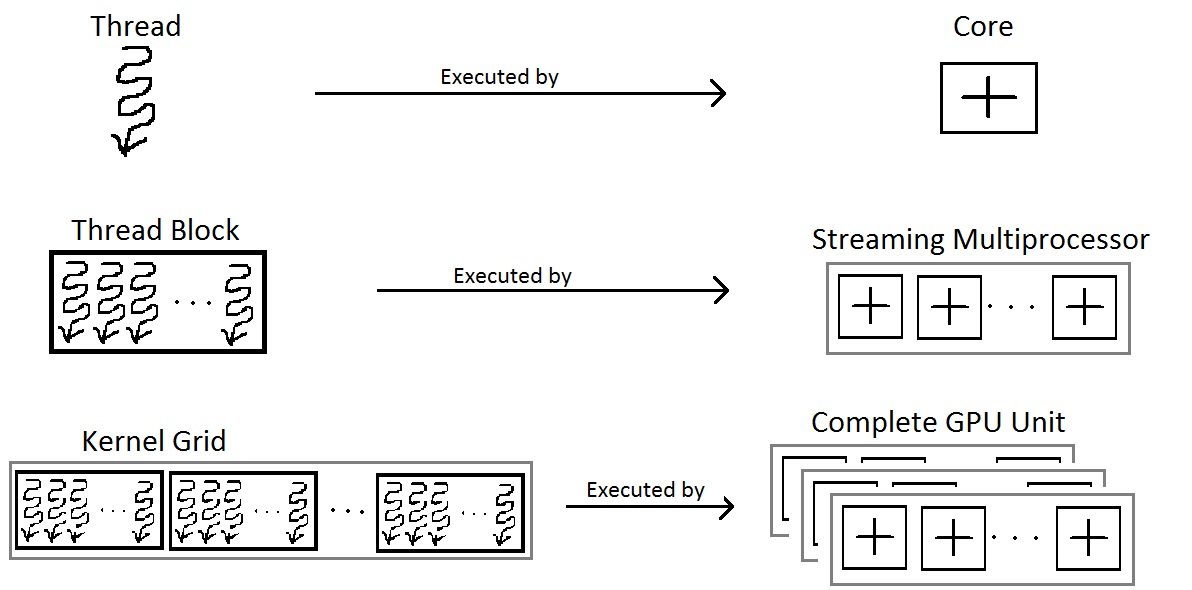
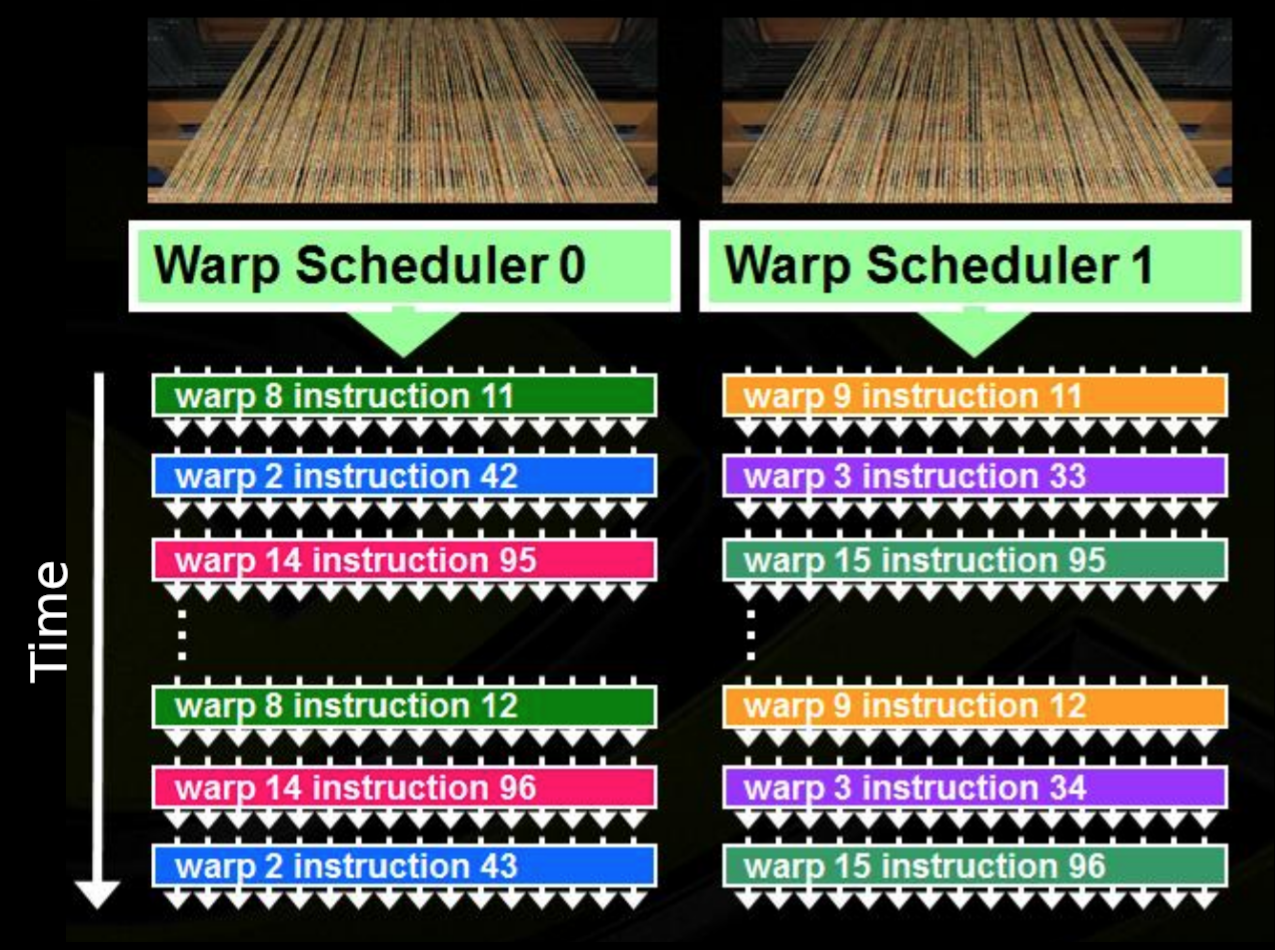
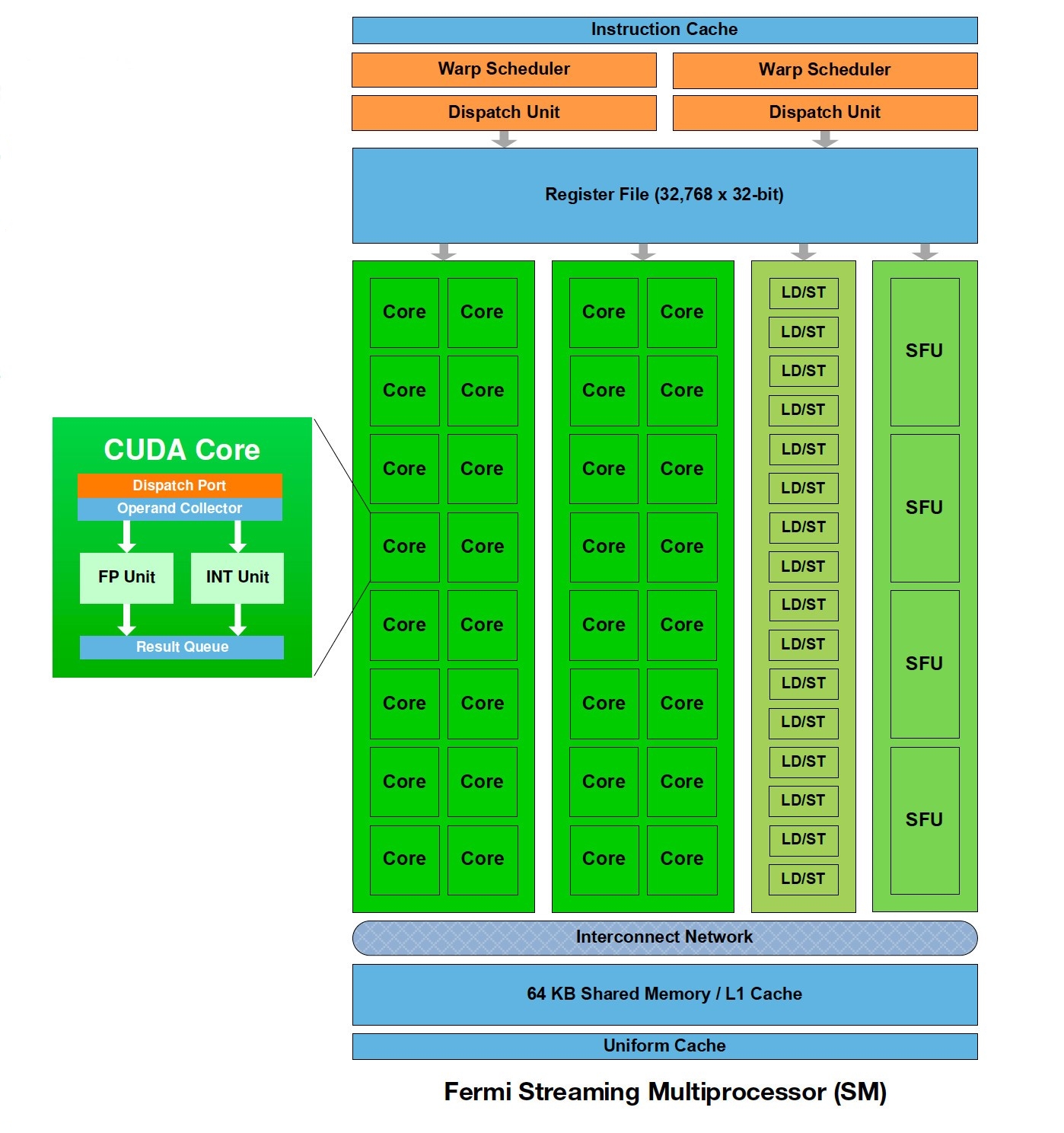
Dimensions of the block/grid
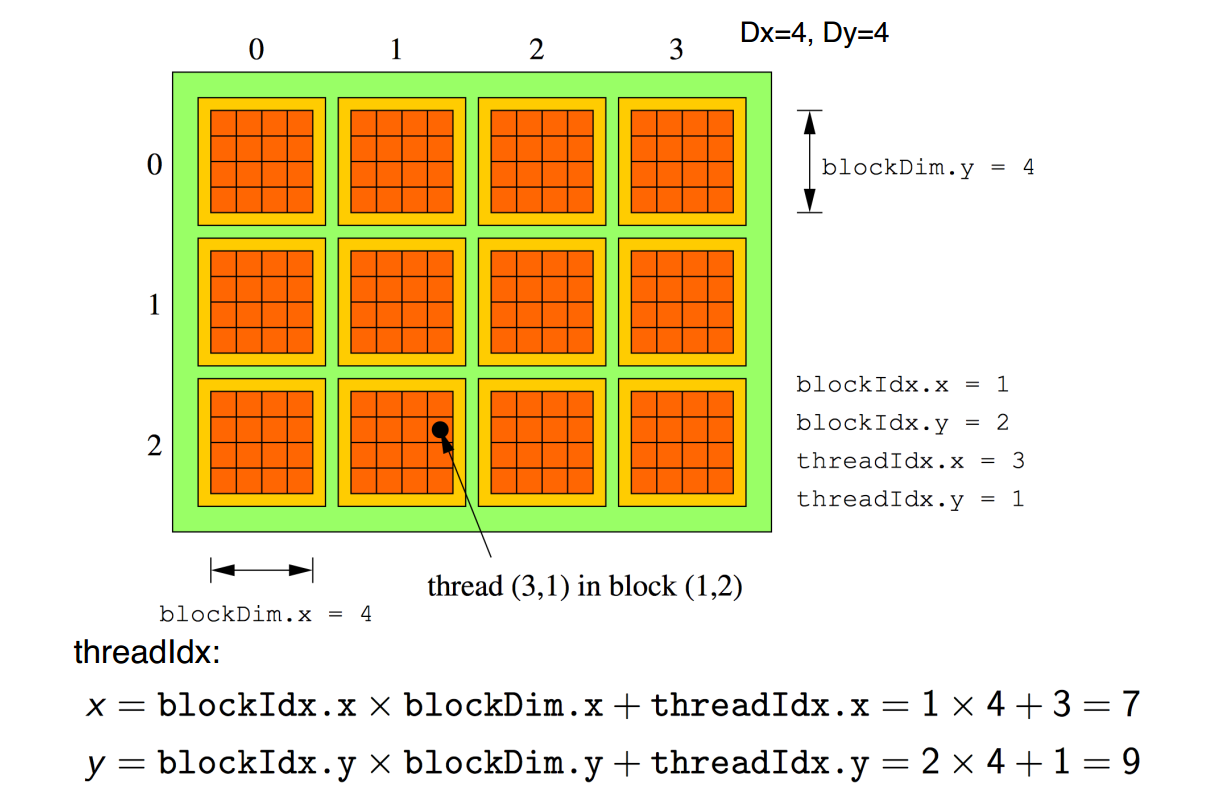
The gridDim and blockDim are 3D variables. However, if the y or z dimension is not specified explicitly then the defualt value 1 is prescribed for y or z.
Declaration of the size of block/grid:
dim3 gridDim // This variable describes number of blocks in the grid in each dimension.
dim3 blockDim // This variable describes number of threads in the block in each dimension.
Setting the dimensions of a kernel
As the blocks may be executed concurrently, the code must be thread \& block independent. Given N as the size of the problem, the block/grid dimenesions can be evalueated as:
// if N is a friendly multiplier of THREADS_PER_BLOCK
my_kernel<<<N/THREADS_PER_BLOCK,THREADS_PER_BLOCK>>>(args)
// if N is not a friendly multiplier of THREADS_PER_BLOCK
my_kernel<<<(N + THREADS_PER_BLOCK-1) / THREADS_PER_BLOCK, THREADS_PER_BLOCK>>>(args);
Calculating threadId
Within the kernel, the following build-in variables can be referenced (in x,y,z-dimension) to calculate tid:
int tid = blockIdx.x * blockDim.x + threadIdx.x;
int threadIdx.x // This variable contains the thread index within the block in x-dimension.
int blockDim.x // This variable contains the number of threads per block in x-dimension.
int blockIdx.x // This variable contains the block index within the grid in x-dimension.
Maximum number of threads in a block
The maximum number of threads in the block is limited to 1024. This is the product of whatever your threadblock dimensions are (x*y*z). For example (32,32,1) creates a block of 1024 threads. (33,32,1) is not legal, since 33*32*1 > 1024.
Source:
Performance Tuning - grid and block dimensions for CUDA kernels
Occupancy is defined as the ratio of active warps (a set of 32 threads) on an Streaming Multiprocessor (SM) to the maximum number of active warps supported by the SM.
Low occupancy results in poor instruction issue efficiency, because there are not enough eligible warps to hide latency between dependent instructions. When occupancy is at a sufficient level to hide latency, increasing it further may degrade performance due to the reduction in resources per thread. An early step of kernel performance analysis should be to check occupancy and observe the effects on kernel execution time when running at different occupancy levels.
NVIDIA Nsights Systems allows for in depth analyze of and application. Some light-weight utils are also available:
computeprof # CUDA profiler (with GUI) from nvidia-visual-profiler package
nvprof ./program # command-line CUDA profiler (logger)
nvprof --print-gpu-trace ./program # shows memory bandwidth
What is the difference between ‘GPU activities’ and ‘API calls’ in the results of ‘nvprof’? https://forums.developer.nvidia.com/t/what-is-the-difference-between-gpu-activities-and-api-calls-in-the-results-of-nvprof/71338/1
Section ‘GPU activities’ list activities which execute on the GPU like CUDA kernel, CUDA memcpy, CUDA memset. And timing information here represents the execution time on the GPU.
Section ‘API Calls’ list CUDA Runtime/Driver API calls. And timing information here represents the execution time on the host.
For example, CUDA kernel launches are asynchronous from the point of view of the CPU. It returns immediately, before the kernel has completed, and perhaps before the kernel has even started. This time is captured for the Launch API like cuLaunchKernel in the ‘API Calls’ section. Eventually kernel starts execution on the GPU and runs to the completion. This time is captured for kernel in the ‘GPU activities’.
Device Query
sudo apt-get install cuda-samples-11-5
cp -r /usr/local/cuda-11.5/samples/ ~/NVIDIA_CUDA-11.5_Samples
cd ~/NVIDIA_CUDA-11.5_Samples/1_Utilities/deviceQuery ./deviceQuery
make
./deviceQuery Starting...
On the Rysy cluster, the output is as follows
./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "Tesla V100-PCIE-32GB"
CUDA Driver Version / Runtime Version 11.5 / 11.4
CUDA Capability Major/Minor version number: 7.0
Total amount of global memory: 32510 MBytes (34089730048 bytes)
(080) Multiprocessors, (064) CUDA Cores/MP: 5120 CUDA Cores
GPU Max Clock rate: 1380 MHz (1.38 GHz)
Memory Clock rate: 877 Mhz
Memory Bus Width: 4096-bit
L2 Cache Size: 6291456 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total shared memory per multiprocessor: 98304 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 7 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Enabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 134 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.5, CUDA Runtime Version = 11.4, NumDevs = 1
Result = PASS
Command line utilities
nvidia-smi # NVIDIA System Management Interface program
cuda-memcheck # checks for memory erros within the program
cuda-gdb # Linux and mac (debugger)
Simple debugging
Compile your application with debug flags -g -G
nvcc -g -G foo.cu -o foo
https://docs.nvidia.com/cuda/cuda-gdb/index.html
Launch your application with debugger, for example Nsight Visual Studio Code Edition plugin for Visual Studio Code.
Acknowledgements
The wide variety of materials provided by nvidia is acknowledgement: